
Algebra
Analyse
Bewijzen
De grafische rekenmachine
Discrete wiskunde
Fundamenten
Meetkunde
Oppervlakte en inhoud
Rekenen
Schoolwiskunde
Statistiek en kansrekenen
Telproblemen
Toegepaste wiskunde
Van alles en nog wat

|






Hoe bereken je steekproefgrootte (vooraf) en de (on)nauwkeurigheid (achteraf)?
Ik ga een klanttevredenheidsonderzoek houden onder onze kopende klanten. Mijn vraag is hoe veel bedrijven moet ik enqueteren om een resultaten met een betrouwbaarheid van 95% te kunnen verkrijgen. Het totaal aantal kopende klanten is 1500. De antwoorden moeten gegeven worden op een schaal van 5 (zeer goed-zeer slecht).
Ik heb geprobeerd om het te berekenen met de formule : s= Wortel uit pxq/n. Waarbij ik er van uit ben gegaan dat er over p en q niets is te zeggen. Voor p en q heb ik daarom 50 gebruikt. Klopt dat? Echter wat moet ik dan voor s gebruiken?
Patric
Student hbo - dinsdag 27 mei 2003
Antwoord
Bij veel onderzoeken bestaat het merendeel van de vragen uit ja/nee vragen, vragen op een 5 puntsschaal (zeer ontevreden - zeer tevreden) en vragen waarbij de keus gemaakt moet worden tussen verschillende voorkeuren. Bij dit soort vragen wil je vaak weten welk percentage voor een bepaald antwoord kiest. In de steekproef kun je dat natuurlijk makkelijk achterhalen. Maar wat betekent dat dan voor de populatie ?
Bij deze schattingen van percentages kun je er op voorhand voor zorgen dat het percentage in de populatie niet teveel afwijkt van het percentage dat je in de steekproef hebt gevonden. Dat doe je door te zorgen dat de steekproef (lees respons) groot genoeg is. Die benodigde steekproefgrootte bereken je als volgt:Situatie 1: berekening steekproefgrootte zonder eindige populatie correctieJe wil een schatting voor een werkelijk percentage geven met 95% betrouwbaarheid en een maximale fout in de schatting van 3%. Bij een schatting voor percentages is de formule voor het betrouwbaarheidsinterval:
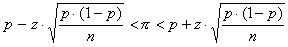
\pi stelt het werkelijke percentage in de populatie voor, p is het percentage dat je in de steekproef vindt. Het verschil tussen \pi en p is de fout in de percentage uit de steekproef. En van die fout in de schatting wil je dat die maximaal 3% (of 5%) is. Dan kun je de benodigde steekproefgrootte berekenen met de formule:
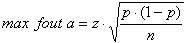
Je kunt nu de formule invullen met fracties (0,03, 0,5, etc.) of met percentages (3%, 50%). In het laatste geval moet je voor die 1 in de formules 100% denken. Vul nu voor de maximale fout de maximale afwijking in die jij voor je onderzoek toelaatbaar vindt dus 3% (of 5%). Die z waarde van 1,96 komt uit de 95% betrouwbaarheid. Voor de p vul je in die waarde waarbij de afwijking het grootst kan worden. Dat is altijd bij p = 50%. Nu kun je de benodigde steekproefgrootte n als volgt berekenen:
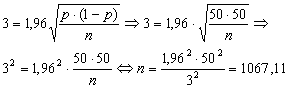
Dit rond je altijd naar boven af. Je vindt dan dus n = 1068.
In sommige boeken zie je voor het berekenen van de steekproefgrootte bij percentageschattingen de volgende formule staan:
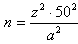
Dat deze formule ook correct is kun je zien in de bovenstaande berekening. Ook hier zal dus 1068 uitkomen.Situatie 2: berekening steekproefgrootte met eindige populatie correctieWanneer je populatie in vergelijking met je steekproef niet al te groot (bijvoorbeeld N=1500) is mag je de steekproefgrootte nog wat verkleinen omdat je steekproef dan al een groot deel van je populatie omvat. Dat mag wanneer de berekende steekproefomvang n meer is dan 10% van de populatiegrootte N. In dit geval met n=1067,11 en N=1500 klopt dat natuurlijk. Als correctie mag je dan (slechts) één keer vermenigvuldigen met de eindige populatie correctiefactor:

Hetgeen een steekproefgrootte van n = 624 oplevert.
Vaak blijkt achteraf dat je je gewenste respons niet gehaald hebt of dat je respons misschien zelfs veel meer dan verwacht is. Wat betekent dat dan voor de onnauwkeurigheid van de schatting van je percentages? Ofwel kun je dan zeggen hoever je schattingen van percentages maximaal afwijken van het werkelijk percentage (met 95% betrouwbaarheid)? Dat kan inderdaad.
Situatie 3: aan de hand van de respons de onnauwkeurigheid berekenen zonder eindige populatie correctieStel je wil bij bedrijven uit een bepaalde branche onderzoeken welk percentage van deze bedrijven uit deze branche gebruik maakt van een bepaald computerpakket.
Je hebt een respons van 500 binnen gekregen. Dan wordt de maximale afwijking van het percentage gebruikers in jouw steekproef ten opzichte van het werkelijke percentage:
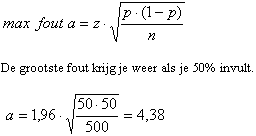
Dat betekent dat (met 95% betrouwbaarheid) jouw schatting maximaal 4,38% zal afwijken van het werkelijke percentage in de populatie.
Wanneer je ook nog weet dat slechts 27% met "ja" geantwoord heeft in de steekproef dan kun je bij deze vraag die maximale fout zelfs verkleinen door de laatste berekening met 27% uit te voeren:
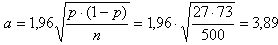 Situatie 4: aan de hand van de respons de onnauwkeurigheid berekenen met eindige populatie correctieStel je wil bij bedrijven uit een bepaalde branche onderzoeken welk percentage van deze bedrijven uit deze branche gebruik maken van een bepaald computerpakket. Je hebt een respons van 500 binnen gekregen.
En je weet dat de hele populatie bestaat uit 1500 bedrijven. Wat betekent dat nu voor de maximale fout in jouw schattingen van percentages? In dit geval kunnen we op deze formule van de maximale fout een correctie voor eindige populaties toepassen. Je steekproefomvang n=500 is namelijk meer dan 10% van de populatiegrootte (1500).
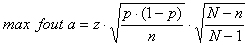
De grootste fout krijg je weer wanneer je 50% invult. Vul nu voor n de steekproef (respons) grootte in en voor N de populatiegrootte:
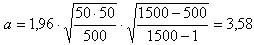
Dat betekent dat (met 95% betrouwbaarheid) jouw schatting maximaal 3,58% zal afwijken van het werkelijke percentage in de populatie.
Natuurlijk is het altijd ook nodig dat je steekproef een goede afspiegeling van de populatie is. Dit heet representatief. Maar dat is een heel ander (en best lastig) verhaal.
Met vriendelijke groet
JaDeX

|
Vragen naar aanleiding van dit antwoord? Klik rechts..!
donderdag 29 mei 2003
|

|
©2004-2025 WisFaq
|