Als archeoloog zit ik, in het kader van mijn proefschrift, met het volgende probleem.
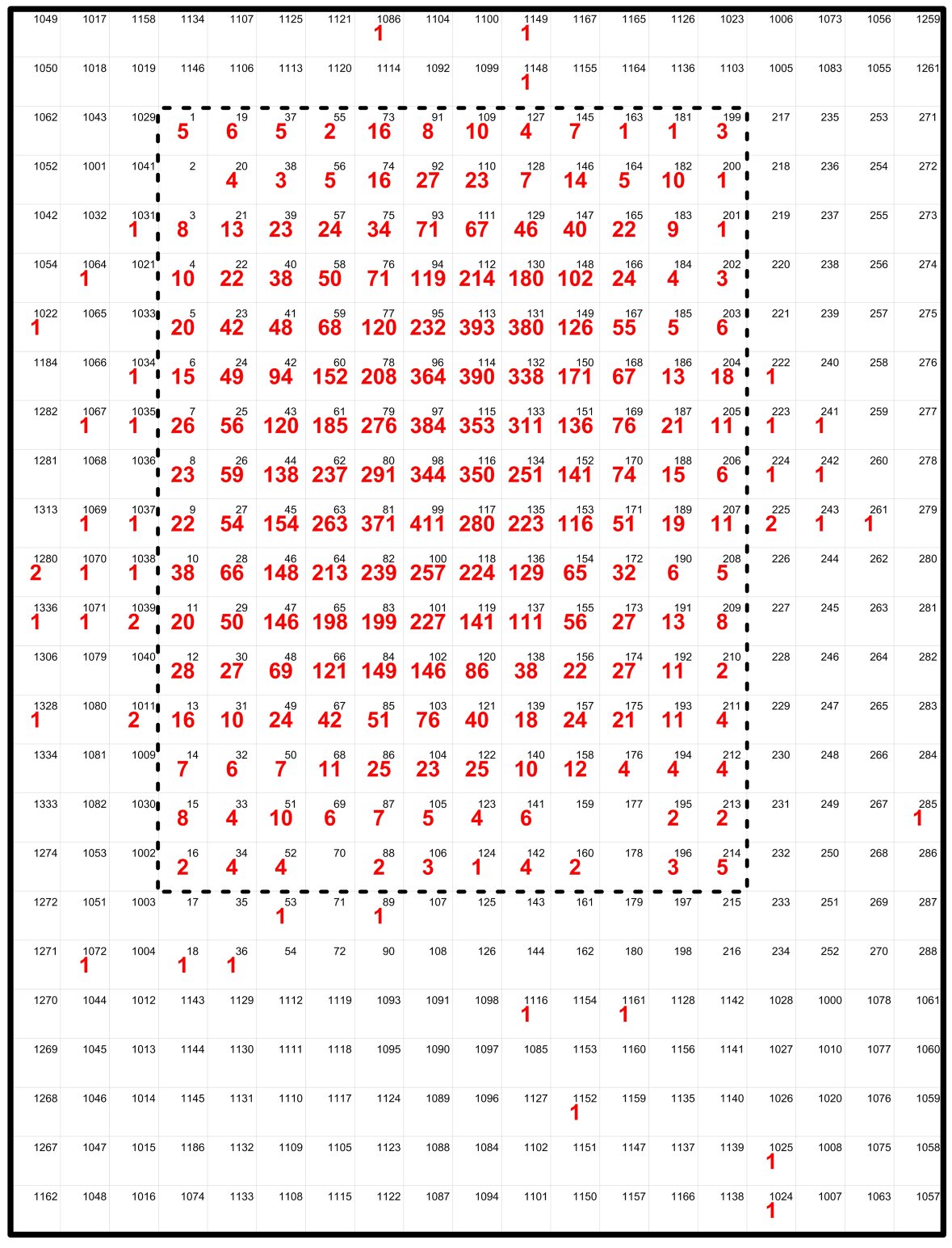
Een archeologische vindplaats uit de steentijden werd opgegraven in vierkante vakken van 50x50cm volgens bijgeleverde figuur, verzonden via plaatjes@wisfaq.nl (de zwarte getallen in elk vak op de figuur zijn het nummer van het vak). Het sediment uit deze vakken werd integraal ingezameld, gezeefd en het zeefresidu vervolgens onderzocht op de aanwezigheid van archeologische vondsten (uit vuursteen). De verdeling van het aantal vondsten per vak is opgenomen in rood op de figuur (bijv. vak 1 telt 5 vondsten, etc.; vakken zonder rood nummer leverden geen vondsten op). Het gaat in totaal om 14.548 vondsten uit 248 vakken.
Nu zou ik graag in het kader van een refitonderzoek (waarbij gepoogd wordt de stenen voorwerpen terug aan elkaar te passen) o.a. een overzicht willen krijgen van alle afstanden die mogelijk zijn tussen twee vondsten (waarbij alle vondsten uit één vak willekeurige x- en y-coördinaten binnen dit vak krijgen aangezien de exacte ligging van de vondsten binnen dit vak niet gekend zijn door de toegepaste opgraafmethode). Hier zit ik met een telprobleem waar ik niet helemaal wijs uit geraak.
benadering 1: Enerzijds en intuďtief denk ik dat het hier eenvoudigweg handelt om een combinatie van twee vondsten uit een populatie van 14.548 elementen, dus 105.814.878 mogelijkheden, m.a.w. vondst 1 uit vak 1 ligt op een afstand van X meter ten opzichte van de overige 14.547 vondsten [en zo verder voor alle vondsten waarbij de afstand tussen vondst 1 en vondst 2 gelijk is aan de afstand tussen vondst 2 en vondst 1 (dus volgorde niet van belang, vandaar combinatie].
benadering 2: Als ik het probleem echter op een andere manier benader, kom ik uit op een totaal afwijkend resultaat. De redenering in deze tweede benadering gaat als volgt: vak 1 telt vijf vondsten, vak 3 telt er acht. Dit betekent dat in beide vakken samen 13 vondsten voorkomen, waartussen dus 78 combinaties van twee vondsten (“vondst-combinaties”) mogelijk zijn.
Op dezelfde manier vergelijk ik alle (14.548 vondsten uit alle) 248 vakken met elkaar. Dit levert dus 30.628 + 248 combinaties van twee vakken (“vak-combinaties”) met telkens X-aantal vondsten per vak op (waarbij de 248 extra vak-combinaties verwijzen naar de onderlinge vergelijking van de vondsten binnen één vak). Voor elk van deze 30.876 vak-combinaties heb ik dus een X-aantal vondst-combinaties.
Tel ik vervolgens alle bekomen vondst-combinaties voor al deze vak-combinaties samen, dan kom ik aan meer dan 490.000.000 mogelijkheden (dus een factor 4.6 hoger dan bij de eerste benadering).
Het is mij niet duidelijk hoe het komt dat de resultaten uit beide benaderingen zo sterk van elkaar afwijken. Het is mij ook niet duidelijk welke van de twee benadering fout is. Het is wel duidelijk dat ik er zelf niet uit geraak.
gunthe
Student universiteit België - woensdag 18 februari 2015
Antwoord
Als ik Methode 2 goed interpreteer tel je daar de afstanden binnen een vak vele malen dubbel: bij de combinatie vak 1 met vak 2 tel je de afstanden in vak 1 mee, en bij de combinatie van vak 1 met vak 3 weer, en zo dus wel 247 keer. Dat tikt lekker aan.
Methode 2 zou ik zo aanpakken/administreren:
alle onderlinge afstanden in elk vakje bepalen, dat geeft 248 aantallen
voor elke combinatie van vakken, zeg vak a en vak b, alle afstanden van punten in a naar punten in b tellen; dat gaat $248\times247/2$ aantallen