|
|
|
\require{AMSmath}



Normaal verdeeld en standaarddeviatie
In een fabriek maakt men machinaal stalen assen. De lengte van de assen is normaal verdeeld. De standaardafwijking in de lengt van de assen is 0,2 mm. Deze standaardafwijking kan worden verkleind door een grotere nauwkeurigheid van de zaagmachine in te stellen. Daardoor duurt het productieproces echter langer. Aan het einde van de productielijn worden alle assen waarvan de lengte meer dan 0,4mm van de ingestelde waarde verschilt verwijderd.
a.Benader m.b.v. vuistregels het percentage uitval.
b.Het in a bepaalde percentage is nogal hoog.Hoe groot moet de standaardafwijkingzijn als er slechts 1% uitval mag zijn?
Ik heb geen problemen om a op te lossen.
o,4 (mm) is gewoon 2.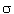 , dus: , dus:
µ-2. Xµ+2. = 95% Xµ+2. = 95%
het percentage uitval is dus 5 %.
Maar vraag b lukt mij niet goed:
mijn leraar doet in zij uitwerking:
Y1=normalcdf(0.4,100,0,x)
Y2=0,005
window 0/1
0/0.1
en dan calc/intersect
X 0,1553 0,1553
dus dan moet ongeveer o,1553 zijn.
maar in het antwoordenboek staat het antwoord:
=0,6
mijn vraag:
ik begrijp dat hij iets geprobeerd te doen met bij y1 normcdf invullen en daarin dan voor de xwaarde die je wilt weten een x invullen en dan bij y2 de ywaarde die bij die xwaarde zou moeten horen invullen en dan met intersect de bijbehorende xwaarde op proberen te sporen.
ik begrijp ook dat er dan bij y2=0,05 moet staan, omdat de stukjes van 0,5 % aan beide kanten van de normale verdeling samen 1%maken. maar ik begrijp niet hoe hij normalcdf nou invult. misschien heeft hij het ook wel fout gedaan, voor die 0,4 laten staan lijkt me raar?
ik zou graag willen weten wat je bij normalcdf in moet vullen om deze som op te lossen en waarom dat zo is.
en het is ook zo dat onze leraar wel over deze methode van oplossen in de klas heeft uitgelegd, dat je voor elke waarde in de normalcdf een x zou kunnen invullen, en dan voor de andere 3 wel een getal. ik vat het wel vaag, maar het kwartje is nog niet helemaal gevallen bij mij:
zouden jullie me dus ook willen uitleggen, misschien aan de hand van een voorbeeld zoals deze som, wat je precies uitrekent als je voor de verschillende waardes bij normalcdf een x invult,en hoe dat komt,dus uitleg voor:
Y1=normalcdf(ingevuld, i, i, x)
Y2=ywaarde die bij x hoort
Y1=normalcdf(ingevuld, i, x, i)
Y2=ywaarde die bij x hoort
Y1=normalcdf(ingevuld, x, i, i)
Y2=ywaarde die bij x hoort
Y1=normalcdf(x,ingevuld, i, i,)
Y2=ywaarde die bij x hoort
alvast heel erg bedankt voor het beantwoorden van mijn vraag!!
anne z
Leerling bovenbouw havo-vwo - zondag 15 december 2002
Antwoord
De functie "normalcdf" gebruikt de volgende parameters:
normalcdf(a, b, m, s) = P(a < X < b).
De methode waar je op doelt kun je gebruiken om de waarde van m of s te gebruiken.
Jouw opgave b) gaat dan als volgt.
Er mag 1% uitval zijn, dus geldt: P(-0,4 < X < 0,4) = 0,99
Dan kun je alle gegevens invullen, behalve s, daar nemen we X voor. Je krijgt:
Y1=normalcdf(-0.4 , 0.4 , 0 , X)
Y2=0,99
Window 0/1 0/1
en dan Calc/Intersect geeft X=0,1553, dus moet s ongeveer 0,1553 zijn. Jouw antwoordenboek is dus fout.
Jouw leraar gebruikte niet de kans P(-0,4 < X < 0,4) = 0,99
maar deze: P(X > 0,4) = 0,005 (de helft van 1%).
Ik zou deze methode alleen gebruiken als je m of s wilt vinden. Als de grens a of b wordt gevraagd kun je beter met de knop "Distr - optie 3: invNorm" werken.
Zo werkt-ie: invNorm(kans dat X < a , m, s) = a .
Voorbeelden:
1. IQ test heeft normaal verdeelde uitkomsten, m = 105 en s = 10. T/m welke score halen de slechtste 15%?
Antw: P(X < a) = 0,15 dus a=invNorm(0.15,105,10) = 94,6
2. IQ test heeft normaal verdeelde uitkomsten,m = 105 en s = 10. Vanaf welke score halen de beste 25%?
Antw: nu geldt P(X < a)=1-0,25=0,75, dus a=invNorm(0.75,105,10) = 111,7

|
Vragen naar aanleiding van dit antwoord? Klik rechts..!
dinsdag 17 december 2002
|

|



home |
vandaag |
bijzonder |
gastenboek |
statistieken |
wie is wie? |
verhalen |
colofon
©2001-2024 WisFaq - versie 3
|
