|
|
|
\require{AMSmath}



Berekening steekproef omvang
Geachte vragen beantwoorder,
Graag zou ik een uitspraak willen doen over de meest waarschijnlijke fout binnen een jaardeclaratie (verzameling van plusminus 50.000 kleinere declaraties) van in totaal € 1.000.000,- met een betrouwbaarheid van 95 % en een nauwkeurigheids marge van 5%.
De steekproef dient getrokken te worden met behulp van de geld-eenheden-steekproef-methode. De populatie eenheid is dus een Euro. Bij het beoordelen van de declaratie, waar de desbetreffende euro in valt, kan blijken de declaratie (en dus ook de euro) voor een deel fout is (0% tot 100%).
Bij een hoger meest waarschijnlijk foutpercentage (over de totale declaratie) dan 1% dient er gecorrigeerd te worden op basis van de meest waarschijnlijke fout.
à Zou u mij aan kunnen geven hoe tot de bepaling van een juiste steekproef omvang te komen?
Zelf heb ik de onderstaande beredenerings wijze gevolgt:
De getrokken gulden kan voor 0% tot 100% fout zijn. Het gevonden foutpercentage wordt echter afgerond. Het gaat hier dus volgens mij om een discrete variabele.
Dat het hier gaat om een discrete variabele wijst in de richting te wijzen van binominale verdeling. Deze kunnen wij volgens mij berekenen middels de poisson verdeling of middels een normale benadering (dankzij de zgn. centrale limietstelling). Welke is het best?
Poisson verdeling
Als criterium geldt dat bij een normale benadering n 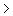 = 20 en tevens n * pi = 5 en n ( 1 – pi ) = 5. Waarbij n = de steekproef grootte en pi = de verwachte kans op succes die wij (met het oog op de maximaal geaccepteerde waarschijnlijke fout) op 1% (0,01) stellen. = 20 en tevens n * pi = 5 en n ( 1 – pi ) = 5. Waarbij n = de steekproef grootte en pi = de verwachte kans op succes die wij (met het oog op de maximaal geaccepteerde waarschijnlijke fout) op 1% (0,01) stellen.
Wanneer wij nu aan de gestelde voorwaarde willen voldoen komen wij op een minimum steekproef omvang van 500 (0,01*5).
Deze grote omvang dient er volgens mij voor voor om te voorkomen dat de verdeling te scheef wordt. Zelf weet ik echter niet hoe relevant dit is daar de linker overschrijdingskans mij minder belangrijk lijkt.
Normale benadering
De populatiefractie (kans op succes) heb ik zoals eerder genoemd op 0,01 gesteld uitgaande van het maximaal acceptabele, meest waarschijnlijk foutpercentage fout van 1%. Voor het berekenen van de steekproef ben ik (voor alle zekerheid) maar uit gegaan van een groter vermoedelijk fout (maximaal te verwachten) percentage van 10% (0,1). De steekproef variatie (s) die hierbij wordt gesteld is p ( 1 – p ) = 0,1 (1- 0,1 ) = 0,09
De gehanteerde nauwkeurigheidsmarge (a) is gesteld op 0,05. Zodoende zou ik op een steekproefgroote van uitkomen 139 uitkomen (1,96*1,96*0,1*(1-0,1))/(0,05*0,05)= 139
Bij voorbaat heel erg veel dank
Gjalt
Ouder - maandag 16 juni 2003
Antwoord
Wat je volgens mij wil (want helemaal duidelijk is het mij niet) is een inschatting maken van het totale foutbedrag in 50.000 declaraties. Twee dingen zijn hierbij van belang namelijk: welk percentage van de declaraties is fout (daar doel je op bij de uitgevoerde berekeningen). Maar ook: wat is bij zo'n foute declaratie het verschil tussen het bedrag op de declaratie en het juiste bedrag. Vervolgens introduceer je een geld eenheden steekproef, iets wat bij mij totaal onbekend is.
De berekening van die Poissonverdeling is wel correct, maar wat betekent dat nu: dat betekent dat je op basis van een steekproef van 500 (foutkans 1%) een normale benadering (met continuiteitscorrectie) zou kunnen toepassen.
Een andere vraag is wat je hebt aan de wetenschap dat je een normale verdeling mag uitvoeren, er zijn voor deze situatie namelijk ook prima Poissontabellen, met het voordeel dat je niet met die continuiteitscorrectie hoeft te rommelen.
Maar er komt ook nog iets anders om de hoek kijken. Stel namelijk eens dat slechts 1% van de declaraties niet klopt, dan wil jij het percentage foute declaraties schatten met een maximale fout van 5%. Snap je wat ik bedoel. Aan die 5% heb je niets op het moment dat het werkelijk percentage in de buurt van de 1% ligt.
Laat ik het nog iets anders proberen te formuleren. Stel je controleert 500 declaraties met foutkans 1% per declaratie, dan is de kans dat je 3 fouten vindt 14%, bij 4 fouten 18%, 5 fouten 18%, 6 fouten 15%, 7 fouten 7%.
In de steekproef is het dus bijna even waarschijnlijk dat je 5 fouten vindt of dat je 3 fouten vindt. Als je op basis hiervan een schatting maakt voor het totale foutbedrag dan ligt de schatting, bij 3 gevonden fouten op iets meer dan de helft van wat het werkelijk is. De moraal is: hier heb je niets aan als je het totale foutbedrag wil inschatten.
Met vriendelijke groet
JaDeX

|
Vragen naar aanleiding van dit antwoord? Klik rechts..!
zaterdag 21 juni 2003
|

|



home |
vandaag |
bijzonder |
gastenboek |
statistieken |
wie is wie? |
verhalen |
colofon
©2001-2024 WisFaq - versie 3
|
