Van een kinderziekte wil men bepalen of er misschien een genetische oorzaak is.Van 1000 gezinnen met kinderen wordt bepaald hoeveel kinderen er zijn en hoeveel kinderen de ziekte hebben gehad.De data bestaan uit paren (n_i,m_i) (1=1,...1000), met n_i=1 het aantal kinderen van gezin i en m_i het aantal kinderen dat de ziekte heeft gehad.
De ziekte heeft kans pi om "in de familie te zitten". Als dit zo is, dan hebben alle kinderen van het gezin kans p1 om de ziekte te krijgen, onafhankelijk van elkaar. Als de ziekte niet in de familie zit, dan hebben de kinderen van het gezin kans p2=p1 om de ziekte te krijgen, onafh van elkaar.Het aantal kindern van een fam is een constante. Ik modelleer m_i als een realisatie van een stochastische variabele M_i.
Ik wil laten zien dat
P_(pi,p2,p1)(M_i=k)={pi[n_i boven k](p1^k)(1-p1)^(n_i-k)}+ {(1-pi)[n_i boven k](p2^k)(1-p2)^(n_i-k)}
Ik heb zelf het volgende, je moet de binomiaalverdeling hier gebruiken, P(X=k)=[n boven k](p^k)(1-p)^(n-k), waarbij hier X=aantal zieke kinderen. Er zijn twee gevallen, 1. Als de ziekte in de fam voorkomt, dan is de kans dat X=k kinderen de ziekte hebben, P(X=k)=[n_i boven k](p1^k)(1-p1)^(n_i-k), ik noem deze uitdrukking q1 2.ziekte komt niet in fam voor, P(X=k)=[n_i boven k](p2^k)(1-2)^(n_i-k)=q2
Nu begrijp ik twee dingen niet: a. pi*q1 b. de som pi*q1+(1-pi)*q2
Welke regels van de kansrek worden toegepast in a en b?
Vriendelijk groeten en dank, Viky
viky
Student hbo - woensdag 10 november 2004
Antwoord
Viky, Je maakt hier gebruik van de volgende stelling: A en B zij gebeurtenissen. P(B)= P(B onder hetgeg.dat A optreedt)P(A)+ P(B onder het geg. dat A niet optreedt)P( niet A). Hopelijk is het zo duidelijk.








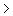 =1 het aantal kinderen van gezin i en m_i het aantal kinderen dat de ziekte heeft gehad.
=1 het aantal kinderen van gezin i en m_i het aantal kinderen dat de ziekte heeft gehad.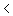 p1 om de ziekte te krijgen, onafh van elkaar.Het aantal kindern van een fam is een constante. Ik modelleer m_i als een realisatie van een stochastische variabele M_i.
p1 om de ziekte te krijgen, onafh van elkaar.Het aantal kindern van een fam is een constante. Ik modelleer m_i als een realisatie van een stochastische variabele M_i.