Leuk dat je bent gaan speuren naar andere verdelingen, maar een Poisson verdeling gaat uit van tellingen waarbij het resultaat in principe van 0 tot oneindig kan zijn. Dat is in jouw geval niet zo. Een hypergeometrische verdeling is,als je slechts 2 mogelijke waarnieming hebt (ja of nee), waarbij je een deel van een beperkte populatie trekt.Als jouw aantal van 3000 computers een vast gegeven is, dan zou je dat kunnen gebruiken, maar ook daar is het wat lastiger direct de benodigde steekproefgrootte te bepalen.
De binomiale verdeling is de juiste keuze als de populatie in principe oneindig groot is.
Zo moeilijk is het niet om de steekproef grootte daarmee te bepalen, maar het hangt er natuurlijk wel van af wat je eigenlijk wilt weten! Wil je weten of het aantal slecht geregistreerde computers nu meer dan 2% bedraagt?? Dan doen je gewoon een hypothese toets, met H0:p=2% en H1:p
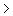 2%. Je wil dan een n gebruiken, zodanig dat de grens waaarbij je H0moet verwerpen niet meer dan 2+3=5% van je steekproef is. Je gaat H0verwerpen als de kans op je gevonden aantal of meer kleiner is dan 2,5% (Het toegestane gebied is 95%,zodat er 2,5% aan beide kanten overblijft.)
2%. Je wil dan een n gebruiken, zodanig dat de grens waaarbij je H0moet verwerpen niet meer dan 2+3=5% van je steekproef is. Je gaat H0verwerpen als de kans op je gevonden aantal of meer kleiner is dan 2,5% (Het toegestane gebied is 95%,zodat er 2,5% aan beide kanten overblijft.)Probeer bijvoorbeeld n=80, en bereken: P(p=0,02;n=80;k
4) Je vindt dan P(k
4)@2,3%. Dus als je 5 of meer slecht geregistreerde computers vindt moet je H0verwerpen.Dat is nog te veel. Bij n=100 is die grens bij 5 of meer. Dat zou net goed genoeg zijn. Wil je echter met een marge van 3% weten wat het nieuwe percentage slecht gerigistreerde computers nu is, dan zal je steekproef groter moeten zijn. Je gaat dan te werk zoals ik in mijn vorige antwoord heb beschreven. Je zou de bovengrens (2+3=5%) kunnen gebruiken, dan mag je al gouw de normale verdeling gebruiken, dus vul in je formule niet 2 en 98% in, maar 5 en 95. Dat maakt al heel veel uit voor de grootte van je steekproef!
Overigens is het bepalen van de benodigde grootte van een steekproef altijd een gok, omdat je van te voren niet weet wat het resultaat is. Daarom gebruikt men in die formule het liefst 50 en 50%, omdat dan de steekproef in iedergeval groot genoeg is. In het algemeen kan je gokken op de boven (of onder-)grens die je toelaatbaar vindt. Bij jouw vraagstelling is dat 5 en 95%.Als je dan echter veel minder vindt, bijvoorbeeld 1%, dan is je nauwkeurigheid wat minder.
Zo duidelijk?
Groet, Ldr.
ldr
8-8-2007