Wanneer je een werkelijk gemiddelde m wil schatten, met 95% betrouwbaarheid bij bekende standaarddeviatie, doe je dat met de formule.
Xgem-z·(s/Ön)
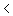 mXgem+z·(s/Ön)
mXgem+z·(s/Ön) Je hebt dan een interval waar je werkelijk gemiddelde met 95% betrouwbaarheid in zit. Als echter de werkelijke standaarddeviatie s onbekend is moet je hem schatten met de s. Maar die s geeft nu een extra onbetrouwbaarheid in de die schatting (tov s). Dan is de vraag waar je dat in de formule zou kunnen compenseren. De enige mogelijkheid is dan de z waarde aan te passen door een t waarde. Die t waarde wordt altijd groter dan de z waarde, hierdoor vermindert de nauwkeurigheid, maar komt de betrouwbaarheid weer terug op 95%.
Des te kleiner de steekproef, des te groter de extra onbetrouwbaarheid en des te groter de compensatie (aanpasssing) in de t waarde zal worden. Dat zie je dan ook terug in de tabel van de t verdeling.
Met vriendelijke groet
JaDeX
jadex
30-5-2003